In post 21.11, we saw that genes are made of DNA and that genetic information is code in the sequence of its bases; more details on the importance of this base sequence were given in post 21.12. But this raises a fundamental question.
How does a DNA sequence determine who we are?
How does my DNA sequence make me into me? And how does your DNA sequence make you into a different person – you? In the language of biology, how does a genotype define a phenotype?
Many of the structures of our body that make us different individuals are built around protein. Skin, bone, hair, muscles all contain proteins. The other components of these tissues are made under the control of catalysts called enzymes that are also proteins. Enzymes control all the chemical reactions in our bodies that determine what happens inside us. Other proteins (immunoglobulins) are responsible for our immunity to disease and others (haemoglobin and myoglobin) transport oxygen; a variant of haemoglobin that occurs in some people is responsible for sickle cell anaemia. Some hormones (chemical messengers) are proteins – for example insulin that controls blood sugar levels; the production of non-protein hormones is controlled by enzymes. (An example of a non-protein hormone is adrenaline that we produce when we are in danger, to increase the blood supply to our muscles to make us stronger). So we can rewrite our original question.
How does a DNA sequence determine the proteins we make?
In post 21.4, we saw that the properties of a protein depend on its sequence of amino acids. So we can rewrite our original question again.
How does a DNA sequence determine the sequences of amino acids in our proteins?
In this post we are going to think about the answer to this question. It would take more posts than I have written in this entire blog to describe all the observations, experiments and techniques that have been involved in answering this question. My aim here is to describe the main ideas that people have had and the conclusions they have reached.
The DNA in our genes never leaves the nucleus of a cell. But proteins are made on particles (about 20 nm long) called ribosomes that are outside the nucleus. (Ribosomes are made of proteins and RNA). Amino acids join together, in the required sequence, on ribosomes.
When cells make protein, RNA is made in the nucleus. The RNA then moves out of the nucleus to a ribosome. This form of RNA is made on the template strand of the DNA double helix. For example, a sequence of bases on DNA, AAGCTGGC, that codes information has a template sequence TTCGACCG that is complementary to the information sequence (remember – A pairs with T and G pairs with C, see post 21.12). Now the sequence of RNA that forms on the template strand has the sequence AAGCUGGC (remember – U replaces T in RNA, see post 21.2). The enzyme RNA polymerase catalyses the polymerisation reaction that joins the nucleotides to make the RNA with this base sequence. The process of transferring genetic information from DNA to RNA is called transcription.
Since this form of RNA carries genetic information from the nucleus to a ribosome, it is called “messenger RNA” this name is usually shortened to mRNA.
The sequence of bases in an mRNA molecule must now be translated into a sequence of amino acids in a protein. So people started to look for an “adaptor molecule” that could recognise bases in mRNA but also contained an amino acid. A form of RNA was discovered that had an amino acid attached to the end of its polynucleotide chain. As we shall see, this form of RNA transfers genetic information into a sequence of amino acids and is called “transfer RNA”; this name is usually shortened to tRNA. A tRNA molecule contains about 80 nucleotide residues.
In the next post, we shall see that there are reasons to believe that three bases in mRNA code for a single amino acid in a protein. This sequence of three bases is called a codon. The sequence of bases in tRNA enables most of the molecule to form stretches of double helix. But there are always three bases in the sequence that are not paired with others. These should be capable of recognising the codon and are called the anticodon. There are different types of tRNA characterised by the amino acid that they carry; each type also has a different anticodon.
Now let’s look at the mechanism for transferring the information in mRNA into a sequence of amino acids in a protein – this process is called translation.
The mRNA molecule moves along a ribosome. As it does, tRNA molecules recognise each codon. When the tRNA molecules are beside each other, on the ribosome, their amino acids join. Gradually a protein is formed. When an amino acid joins the protein chain, its tRNA leaves the ribosome. The RNA in the ribosome (“ribosomal RNA” or rRNA) is a catalyst for the reactions involved in translation. So the sequence of amino acids in the protein depends on the sequence of bases on mRNA and, ultimately, on the sequence of bases in DNA.
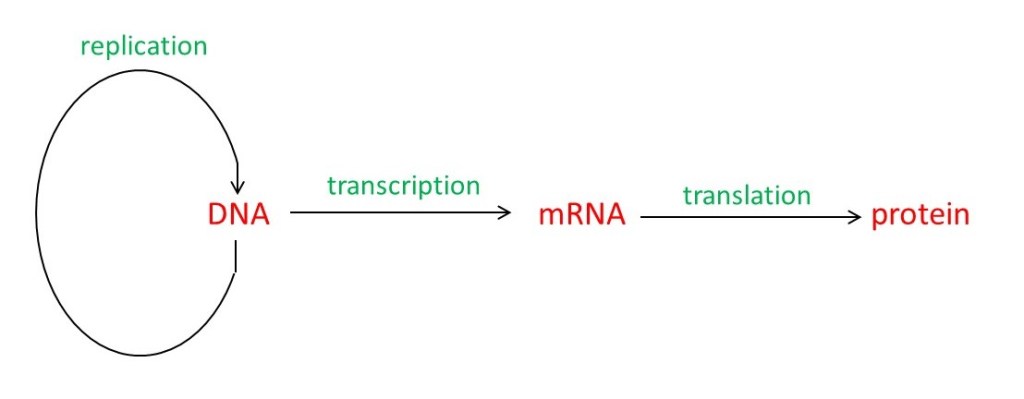
The diagram at the beginning of this post shows how genetic information is transferred in protein synthesis. It also shows that the information in DNA can be copied to make new DNA in the process of replication (post 21.14). There are other ways in which genetic information can be transferred (see https://en.wikipedia.org/wiki/Central_dogma_of_molecular_biology ) but the diagram shows what we need to know to answer the question: how does a DNA sequence determine the sequences of amino acids in our proteins?
Related posts
21.8 Genes
21.11 Genes are made of DNA
21.12 The DNA double helix
21.14 Copying genetic information
