Before you read this, I suggest you read post 21.13.
When Crick and Watson proposed that the molecular structure of DNA was a double helix, it immediately suggested to them a mechanism for how genetic information could be copied during cell division in mitosis and meiosis. This mechanism was based on the idea that genes are made of DNA (see post 21.11).
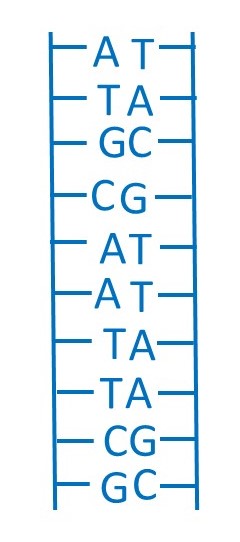
The picture above shows two strands of DNA joined together by base pairs. Let’s suppose that the sequences of bases on the strand on the left contains the genetic information. Then the sequence of bases on the right is complementary to the information sequence and forms a template for making a new information sequence. In the Crick and Watson model, the two strands form a double helix but their ideas about copying genetic information is easier to explain with the simple two-dimensional pictures that I’m using here.
Reading from the bottom up, the genetic information sequence is:
GCTTAACGTA.
So the complementary sequence is:
CGAATTGCAT,
since G pairs with C and A pairs with T (see post 21.12).
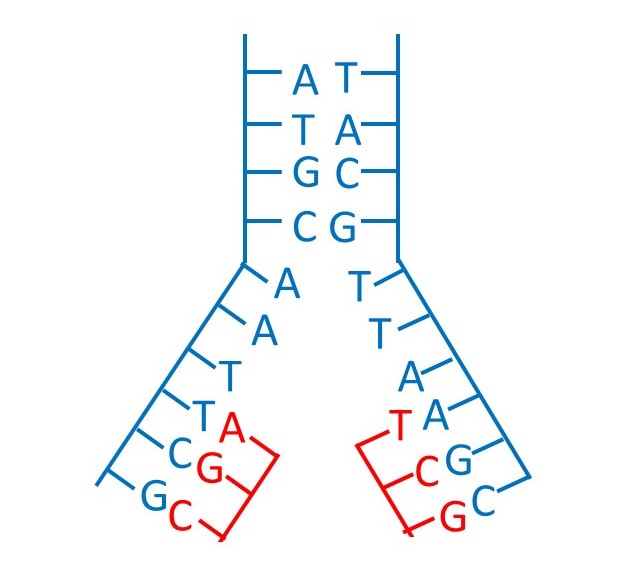
The idea is that the double helix uncoils so that the genetic information can be copied. The cell contains nucleotides (otherwise it wouldn’t be possible for it to make new DNA). Nucleotides with the base C then bind to G on the uncoiling DNA strand. Nucleotides with G bind to C on a DNA strand; nucleotides with T bind to A and nucleotides with A bind to T. The nucleotides then join together to make a new DNA strand. Two new strands form: one is complementary to the information strand, the other is complementary to the template strand. In the picture above, the new strands are shown in red.
Each pair of new (red) and old (blue) strands then coils to form a double helix that is identical to the original. So two identical double helices have been formed that are copies of the first. This means that genetic information has been copied.
An important feature of this idea is that a new double helix contains one old (blue) and one new (red) strand; this feature is called semi-conservative replication.
The American biologists Mathew Meselson (1930-) and Franklin Stahl (1929-) performed a experimental test of the semi-conservative replication hypothesis. They grew the bacterium Escherichia coli with nutrients that contained the usual nitrogen isotope N14. This was generation 0 for their experiments. The nutrients were then replaced by those containing the nitrogen isotope N15 that has a higher density. A new DNA strand would then have a higher density than an old DNA strand because its molecules were made from nutrients with nitrogen atoms of higher density. The next generation of bacteria would be generation 1. They continued to be fed nutrients containing N15 instead of N14 and became the parents of generation 2.
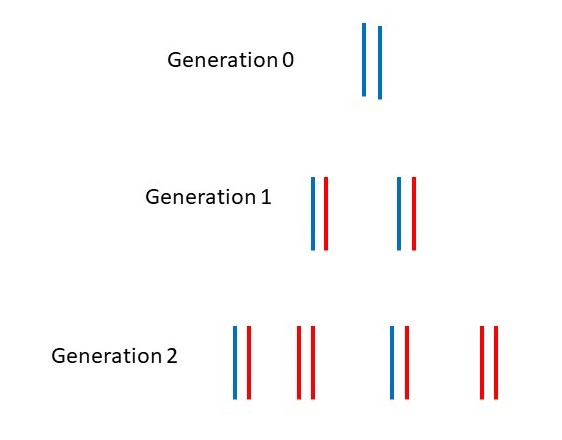
The picture above shows the DNA molecules, predicted by semi-conservative replication, in each generation; old DNA strands are blue, new DNA strands are red. In generation 0, both strands are blue. According to semiconservative replication, in generation 1, DNA molecules will be formed with one blue strand and one red strand. In generation 2, new molecules will be formed by adding a red strand to each blue and to each red strand. So, in generation 0, all molecules will be low density; in generation 1, all molecules will be medium density and, in generation 2, there will be equal numbers of medium and high density molecules.
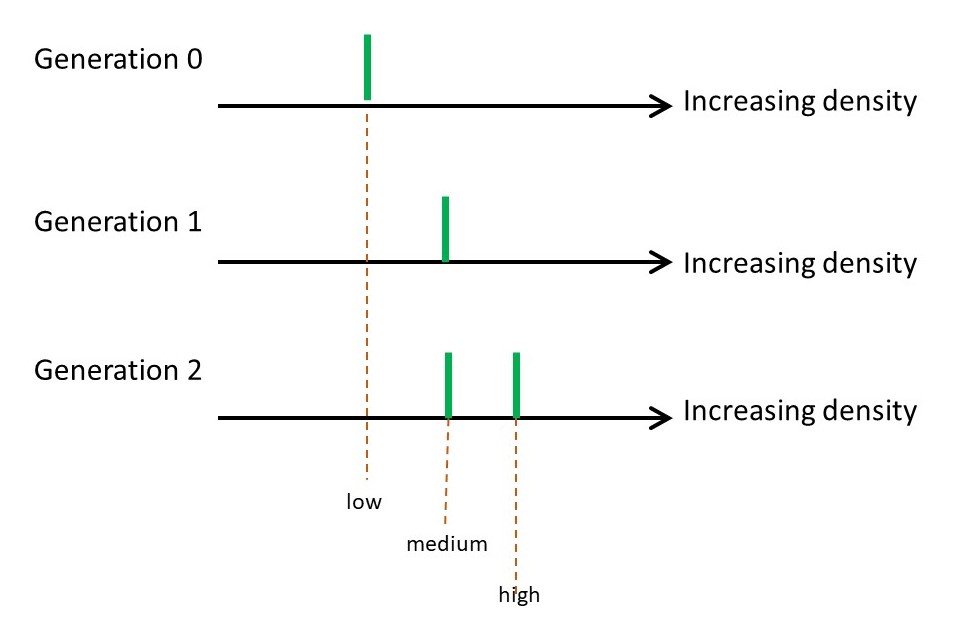
Meselson and Stahl extracted DNA from each generation and determined the relative density of its molecules by density gradient ultracentrifugation; the results are shown above where the peaks showing the positions of the molecules are shown in green. The results are the same as predicted by semiconservative replication.
Be careful! These results do not prove that semi-conservative replication is correct – an experiment can never prove that an hypothesis is true, only that it is false (posts 16.2 and 16.3). However, the results are consistent with the semi-conservative replication hypothesis that is currently our best explanation of how generic information is copied.
Related posts
21.12 The DNA double helix
21.11 Genes are made of DNA
21.10 Chromosomes 2
21.9 Chromosomes 1
21.8 Genes
21.2 Nucleic acids
Follow-up posts
