DNA is an example of a nucleic acid. Its name is an abbreviation for deoxyribonucleic acid. It was discovered in 1869 by a Swiss doctor called Friedrich Miescher (1844-1895). Most people know that DNA is responsible for coding genetic information but may not know much about its chemical composition, how it codes this information or how we know that this is its function. This post is about its chemical composition; in later posts I hope to consider the evidence for what it does and how it does it.
DNA is not the only nucleic acid – the other is RNA, ribonucleic acid.

Nucleic acids are condensation polymers consisting of nucleotide residues. So what is a nucleotide? It is derived from phosphoric acid H3PO4 whose structural formula is shown above. (Remember that a molecule like this is not flat – the bonds between the phosphorus atom and the four oxygen atoms point towards the corners of a tetrahedron, so the group is like a tetrahedral molecule). In a nucleotide, one of the hydrogen (H) atoms is replaced by a sugar residue; the specialist words to described sugars and the way their chemical structures are represented can be found by following the previous link. There are points in the structure where bonds join but I have not put in the symbol for an atom; there is a carbon atom at each of these points. I have not shown all the hydrogen atoms but you can work out where they are because each carbon atom forms four bonds. The picture below shows the sugar β-D-deoxyribose, that occurs in DNA, with the numbers (in red) that are used to label its carbon atoms; β-D-ribose, that occurs in RNA, has an -OH group on carbon atom C2.
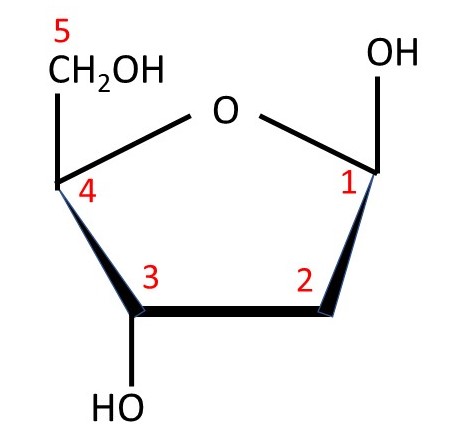
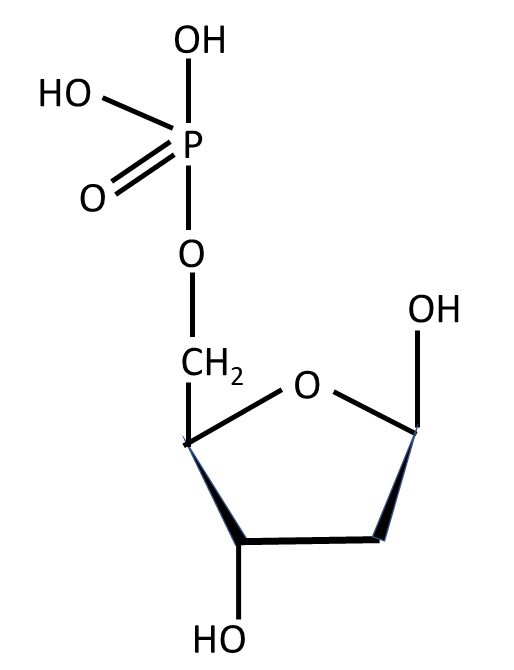
In a nucleotide, a hydrogen atom is lost by one of the OH groups of phosphoric acid and the OH group is lost from carbon atom C5 of a sugar to form a water (H2O) molecule and, when the sugar is β-D-deoxyribose, the result shown below.
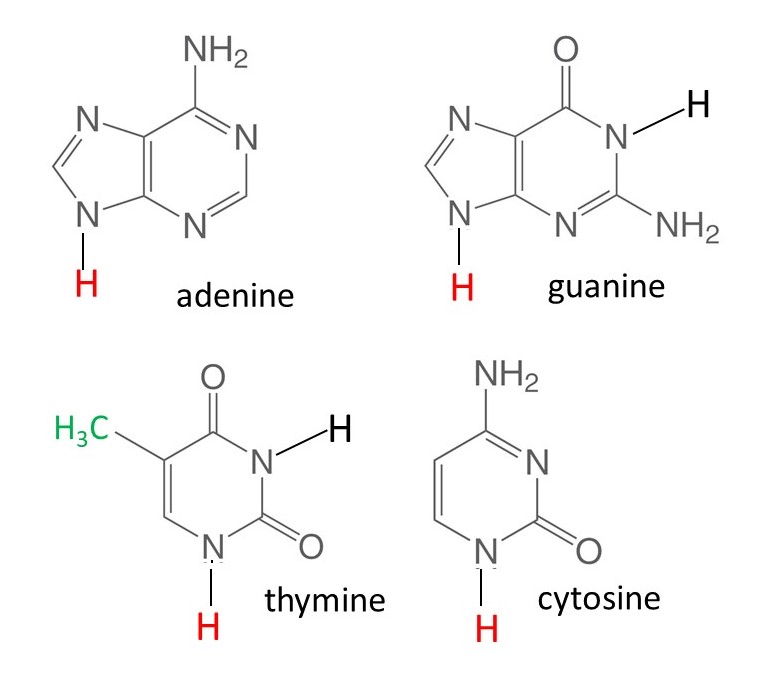
Also, in a nucleotide, the OH group on the carbon atom C1 is replaced by a molecule of a purine or a pyrimidine. In DNA, the purine can be adenine or guanine; the pyrimidine is thymine or cytosine. The structures of these compounds, that are often called the bases in nucleic acids, are shown below. (in these pictures I have used the same simplified way of representing structural formulae as I did for sugars.) In RNA, uracil (in which the green -CH3 group of thymine is replaced by a hydrogen atom) replaces thymine and some other bases can also occur. The bases are flat molecules because rotation about double bonds is not allowed.
The base loses its (red) hydrogen atom, when it attaches to the sugar residue, so that a nucleotide (like that shown below) and a water molecule are formed.
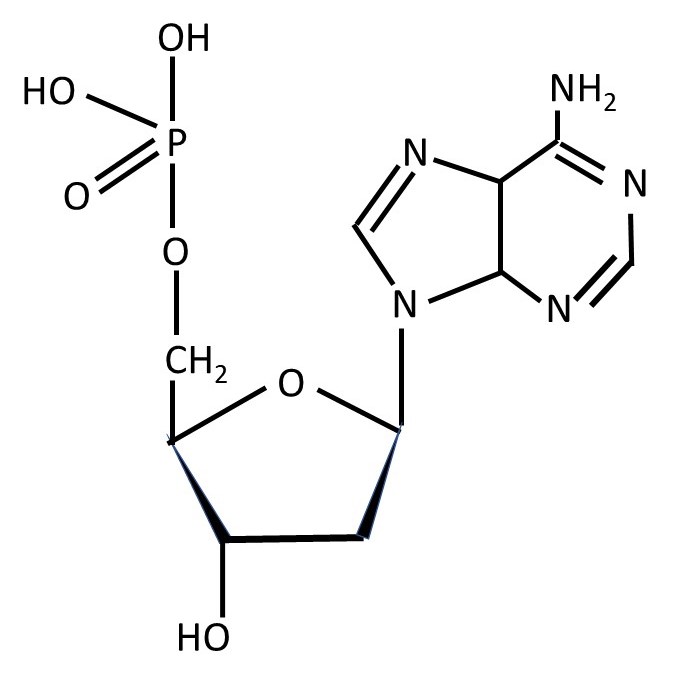
The structural formula of a nucleotide in which the sugar is β-D-deoxyribose and the base is adenine is shown above.

A nucleic acid is a condensation polymer composed of a sequence of nucleotide residues. Another name for a polymer like this is a polynucleotide. The way in which two nucleotides join together is shown above.
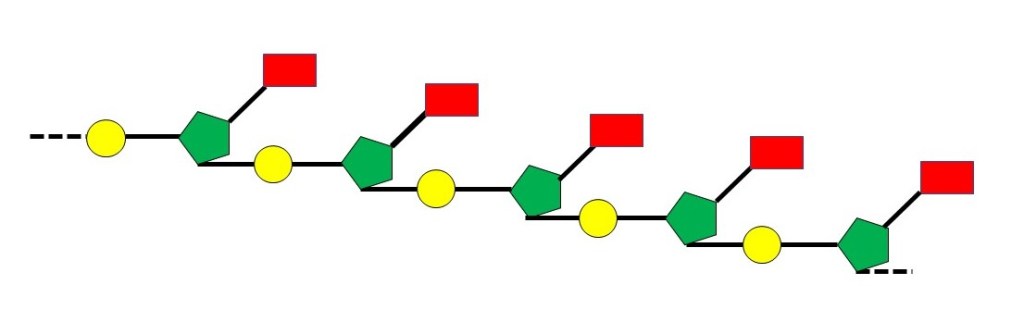
The chemical structure of a nucleic acid schematically in the picture above, where the yellow circle represents a phosphate group, the green pentagon represents a sugar group and the red rectangle represents a base. In later posts, I will use similar representations of a nucleic acid; the exact form will depend on the idea that I wish to explain.
The America biochemist (born in Austria) Erwin Chargaff (1905-2002) analysed many samples of DNA in the late 1940s and early 1950s. He made the surprising discovery that, in any sample, the number of adenine residues was equal to the number of thymine residues and that the number of guanine residues was equal to the number of cytosine residues. If you read the scientific papers in which he reported this work, you will see that he could not explain these results. It was not until 1953, when Francis Crick and James Watson proposed a model for the three-dimensional structure of DNA that Chargaff’s result could be explained and their importance realised. Chargaff had discovered something important, for reasons to be explained in a later post, without realising it. Many accounts of Chargaff’s work exaggerate what he discovered, as did Chargaff himself – after 1953 (before then he had described Crick and Watson as “clowns”). The reality is that he analysed a lot of DNA samples and obtained important results but did not understand the significance of them.
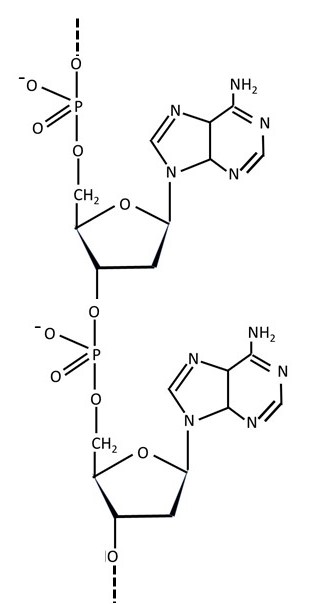
Phosphoric acid is a strong acid, so we would expect a nucleotide to be a strong acid. The O-H bond on the phosphorus atom will then break to give a hydrogen ion (H+) and a negatively charged ion, so we would expect that a nucleic acid would have -O- groups (not -OH groups) along the nucleotide chain, as shown above. A polymer that is negatively charged in this way is called a polyanion. Other examples of polyanions are the polysaccharides agarose, hyaluronan and heparin. We expect the positive charges in the polyanions derived from nucleic acids to be balanced by positive ions – for example, H+, Na+ and Ca2+
You may know that the three-dimensional structure of the DNA molecule is a double helix. But to think about this structure and why it is important, we will first need to think about several other topics that will be covered in later posts.
This blog has an INDEX.
Related posts
20.40 Polysaccharides
20.38 Sugars
Follow-up posts
