It would be useful to read posts 16.8 and 16.42 before you read this.
Two previous posts (16.8 and 16.42) were about a biologist who developed a simple model to predict the number of rabbits on a farm. It took him 5 years to collect the data to develop his model. He then used it to predict the rabbit population in 20 years-time. The model overestimated the number of rabbits by over 900.
In post 16.42, we saw that the biologist should have tested his model before making predictions about the future. How could he have done this? His model was developed after 5 years of counting rabbits. He could have continued counting the rabbits for another 5 years. This second set of data could have been used to test the model. The table below shows the results predicted by the model, the observed number of rabbits and the difference between them.
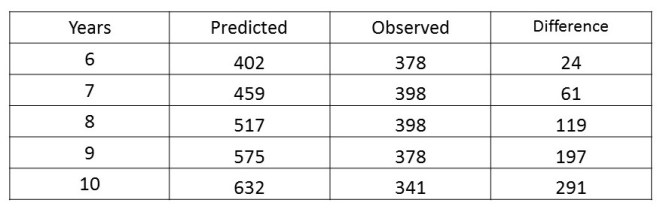
It is clear, from the table, that the difference between the predictions of the model and the observed number of rabbits increases with increasing time.
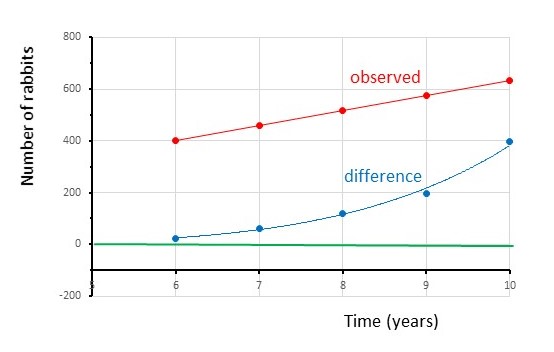
The graph (above) also shows that the model is not working. If the model predicted exactly the number of rabbits, the difference between observed and predicted numbers would always be zero. So, the blue data points would lie on the horizontal green line. In practice, we wouldn’t expect the model to predict the exact number and we wouldn’t expect to always count the exact number of rabbits – some might be hiding and we might count some of them twice. As a result, we would expect the blue data points to be randomly distributed above and below the green horizontal line (see posts 16.24 and 16.26) – if the model worked well.
Instead the deviation of the data points from the green line increases as time passes. So, we can’t use the model to make predictions about the future.
The process of testing is an essential step of developing a model to predict how something will behave. This process of testing the model is sometimes called validation. But remember, testing can show that a model makes incorrect predictions – it can’t prove that the predictions of a model will always be correct (post 16.3).
Engineers often use very sophisticated computer software to predict mechanical stresses in objects (Finite Element Analysis, FEA) and the flow of liquids and gases (Computational Fluid Dynamics, CFD). The software is very reliable, but they still need to test their models. Why? Because the software requires that they input a description of the system they are modelling and values for the properties of the stuff being modelled. There are also many options about how they decide to use the software. So, once again, testing is an essential stage in the modelling process- before making predictions.
Related posts
16.42 Keep it simple
16.28 Significant differences
16.26 Normal distribution
16.24 Accuracy and precision
16.8 Predictions
16.3 Scientific proof
Follow-up posts
